22.12.2015 16:59
На днях в Москве состоялась конференция, посвященная теме Big Data. В ее рамках обсудили развитие данного направления в мире и сравнили с текущим положением дел в России. Наша страна, конечно, еще не может похвастать серьезными цифрами в этой сфере - из общего объема рынка, который по итогам 2015 года должен составить $33,3 млрд, на Россию придется лишь порядка $300 млн. Тем не менее, темпы роста по Big Data у нас стремительно растут, опережая общерыночные. Поэтому уже в перспективе нескольких лет наша доля на мировой арене может вырасти с текущих 1,2% до 3%.
Если говорить о глобальных прогнозах, то по подсчетам компании IDC, к 2019 году рынок вырастет на 23% CAGR и составит $48,6 млрд. Есть и более позитивный прогноз от сообщества Wikibon, представители которого считают, что объем рынка через четыре года достигнет $55 млрд.
По мнению компании Data-Centric Alliance, для рынка это означает, что память как таковая будет дешеветь, но при этом hardware-продукты и услуги будут становиться дороже ввиду необходимости постоянно совершенствовать возможности обработки данных (параллельность процессов, распределение и дублирование информации).
"Сервисы выходят на первый план — компаниям и организациям становятся нужны знания, результат анализа и возможность зарабатывать/экономить на основе этих знаний. Иными словами, на первое место в работе с данными выходит интерпретация", - отмечают в DCA.
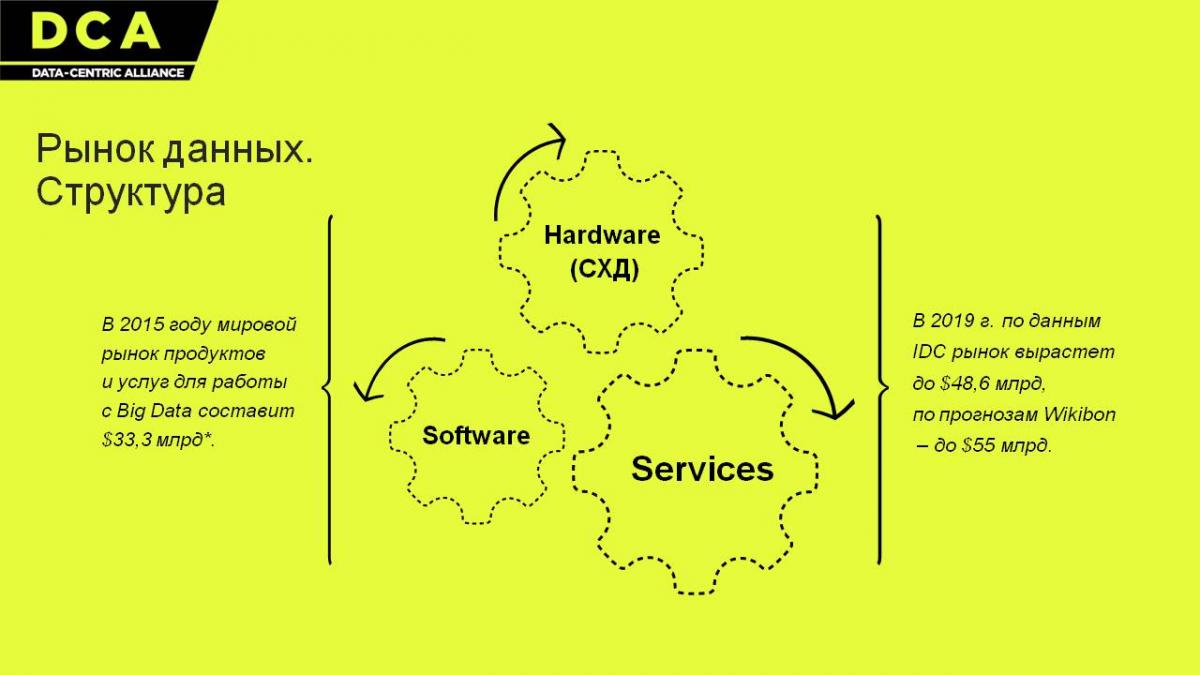
Именно в этой связи интересно будет наблюдать за развитием Software'ного сегмента (под ним подразумевается круг софтверных решений для работы с данными), считают эксперты. Кстати, по прогнозам IDC, именно этот сегмент продемонстрирует наибольший рост - 26,2%. По их же данным, растущая цена "софтверных" продуктов может сыграть отрицательную роль, задержав рост рынка больших данных.
"На наш взгляд, это происходит по причине "взросления" рынка — клиенты лучше понимают, что и зачем им нужно и сколько они готовы платить, поставщики решений, видя сформированную потребность, осознают сложность поставленных задач и повышают цены", - комментирут представители DCA.
Что до российского рынка, то здесь развитие Big Data будет зависеть в первую очередь от экономической обстановки. По мнению экспертов, она разделит крупный бизнес на две глобальные части, одна из которых будет быстрее и активнее переходить на Data-driven подходы к бизнесу и внедрение систем поддержки принятия решений, вторая же сконцентрируется на решении краткосрочных задач, а значит, может оказаться догоняющей в момент, когда экономика начнет расти.
"Первая группа (те, что начнут активнее внедрять Data-driven технологии) уже, по сути, находится в процессе поиска/внедрения технологических решения на рынке, а значит в 2016 году появятся еще публичные кейсы успешного применения технологий анализа данных", - заявляют в DCA.
Еще одним немаловажным фактором развития Big Data в РФ станет государственное регулирование. Аналитики считают, что рано или поздно рынок данных привлечет внимание регулирующих органов. В этом случае отрасли необходимо иметь четкие представления о том, какие сферы деятельности регулирование оздоровит и простимулирует, а какие лучше оставить без государственного вмешательства.

В продолжение разговора об отечественном рынке, представители DCA отметили, что на текущий момент у нас работает 12 узкоспециализированных поставщиков обезличенных данных. Еще два игрока недавно перешли под контроль Сбербанка России (речь о компании Segmento) и "Ростелекома" (оператор стал обладателем 75% акций компании IQ Men, российского разработчика платформы, использующей технологии Big Data. За актив РТК заплатил 525 млн рублей). Помимо этого "Ростелеком" сообщил о создании на базе департамента венчурных продуктов РТК и поисковика "Спутник" технологического центра в области анализа больших данных. Этот ресурс призван повысить эффективность бизнеса оператора за счет анализа данных об использовании интернета, метрик канала передачи данных и биллинга.
Поскольку конференция касалась темы Big Data в целом, а не телевизионного сегмента, мы попросили представителей компании DCA поделиться с нами некоторыми подробностями относительно использования "больших данных" операторами платного ТВ и онлайн-кинотеатрами. На наши вопросы ответил Кирилл Чистов, директор по развитию бизнеса компании DCA.
Кабельщик: Какое количество ТВ-операторов уже сейчас активно использует в своей работе Big Data?
Кирилл Чистов: Насколько нам известно, аудиторные данные и различные платформы для их обработки для оптимизации бизнес-процессов и повышения отдачи от маркетинга уже используют почти все крупные провайдеры ШПД и цифрового ТВ, включая Nemo TV, Tvigle, "Триколор" и других. Степень активности внедрения и использования, однако, определить сложно.
К.: Из всего объема собираемых оператором данных, какое количество, как правило, используется в конечном счете для работы (условно, из 70 собранных параметров, для дальнейшего анализа важны и используются только 20)?
К.Чистов: Сложно сказать, какой объем собираемых данных используется для дальнейшего анализа, сегодня потоки данных растут в геометрической прогрессии, но основная их часть попросту не может быть использована в существующих моделях обработки.
Тем не менее, Паретто чаще всего прав (±20% данных дают ±80% эффекта), но не всегда заранее очевидно, какие именно данные принесут пользу. Многое зависит от объема и актуальности данных, дополнительных (в т.ч. внешних) факторов. Кроме того, операторам и провайдерам сегодня все интереснее обогащать свои данные внешними — например, данными о поведении пользователей в Сети с последующей "связкой" с абонентской базой на своей стороне. Таким образом, в распоряжении компании оказывается не просто информация о том, как абонент использует сервис, но и о его интересах и других поведенческих характеристиках. Чем полнее интегральный профиль абонента, тем лучше компания понимает, что ему нужно, тем эффективнее строится коммуникация с ним.
К.: А в каком направлении сейчас чаще всего используются собираемые данные — для маркетинговых акций, формирования пакетов, попыток персонализировать сервис, рекламы, чего-то иного?
К.Чистов: У всех операторов и провайдеров есть две ключевых задачи: сокращать отток и повышать ARPU. Именно здесь оказываются полезными технологии обработки данных (платформы и IT-решения) и внешние данные (как "сырье" для этих платформ). Платформы для предиктивной аналитики, на основе данных оператора и внешних данных, анализируют поведенческие паттерны абонентов, сегментируют их, выделяя постоянных и лояльных, тех, кто уже в поиске новых решений для себя, и группу риска, например. Первым можно сделать небольшой бонус за лояльность, вторым предложить новое решение, аналогичное текущим рыночным или лучше, а группу риска исследовать детальнее, для выявления очевидных моделей взаимодействия.
Работа предиктивной аналитики строится по принципу выявления "триггеров" — событий, отражающих намерения абонента: "заходил на 3-5 сайтов других провайдеров за последнюю неделю" — высока вероятность ухода к конкуренту, "стал меньше взаимодействовать с сервисом" — возможно, нужна альтернатива или упало качество. В обоих случаях, зная заранее, провайдер может предпринять меры по удержанию абонента.
С повышением ARPU логика та же: "триггер" указывает на готовность/необходимость дополнительных услуг, маркетинг формирует индивидуальное предложение, отдел продаж/колл-центр связывается с абонентом и завершает сделку.
К.: Есть ли оценка, какие деньги за последние год-два операторы потратили на Big Data? "Ростелеком", например, недавно объявил о создании собственного техцентра в этой сфере.
К.Чистов: Точных цифр нет: рынок Big Data очень слабо очерчен, особенно в России. Тем мне менее, с высокой долей уверенности могу сказать, что в сумме (системы хранения + ПО + сервис + содержание штата аналитиков и консультантов) уже сегодня составляют не менее $200 млн. Но только в последний год эти расходы стали выделяться в отдельную статью с намеком на "Большие Данные" в формулировке.
К.: А что по поводу использования "больших данных" онлайн-кинотетарами? Это тот сегмент, который не в меньшей, а то и в большей степени заинтересован в big data.
К.Чистов: Если говорить про digital-медиа, к которым относятся как раз онлайн-кинотеатры, то здесь аудиторные данные применяются, например, таким образом:
Персонализация. Зная о предпочтениях и интересах пользователя можно, например, полностью адаптировать под каждого главную страницу — наполнив ее контентом, который будет интересен и востребован именно таким пользователем. Это очевидная история, многие медиа уже так делают. Но как быть, если пользователь пришел к вам впервые, и вы о нем ничего не знаете? Можно подключить так называемые внешние данные — от какого-нибудь агрегатора, типа Facetz.DCA. Система аналитики в течение сотых доли секунды определяет интересы только что пришедшего пользователя и оптимизирует выдаваемый ему контент. Зритель получает персонализацию сервиса с первой секунды общения, а сайт — большее количество просмотров и продаж контента.
Анализ аудитории. Очень подробная сегментация аудитории позволяет тем медиа, кто работает по рекламной модели более таргетированно ее продавать, а тем, кто продает контент) — понять, кто те люди, которые его покупают и как строить с ними отношения.
У ряда интернет-кинотеатров ведется работа по анализу данных смотрения для выявления определенных закономерностей роста популярности того или иного контента и планирования его будущих закупок. Контент стоит достаточно больших денег и в случае провала в просмотрах появляются большие риски недополучения рекламных бюджетов. Это направление достаточно новое и сложно прогнозируемое, так как зависит от эмоциональной составляющей, но несмотря на это, привлекает все больше внимания.
К.: Спасибо!
Темы
- Войдите или зарегистрируйтесь, чтобы оставлять комментарии







