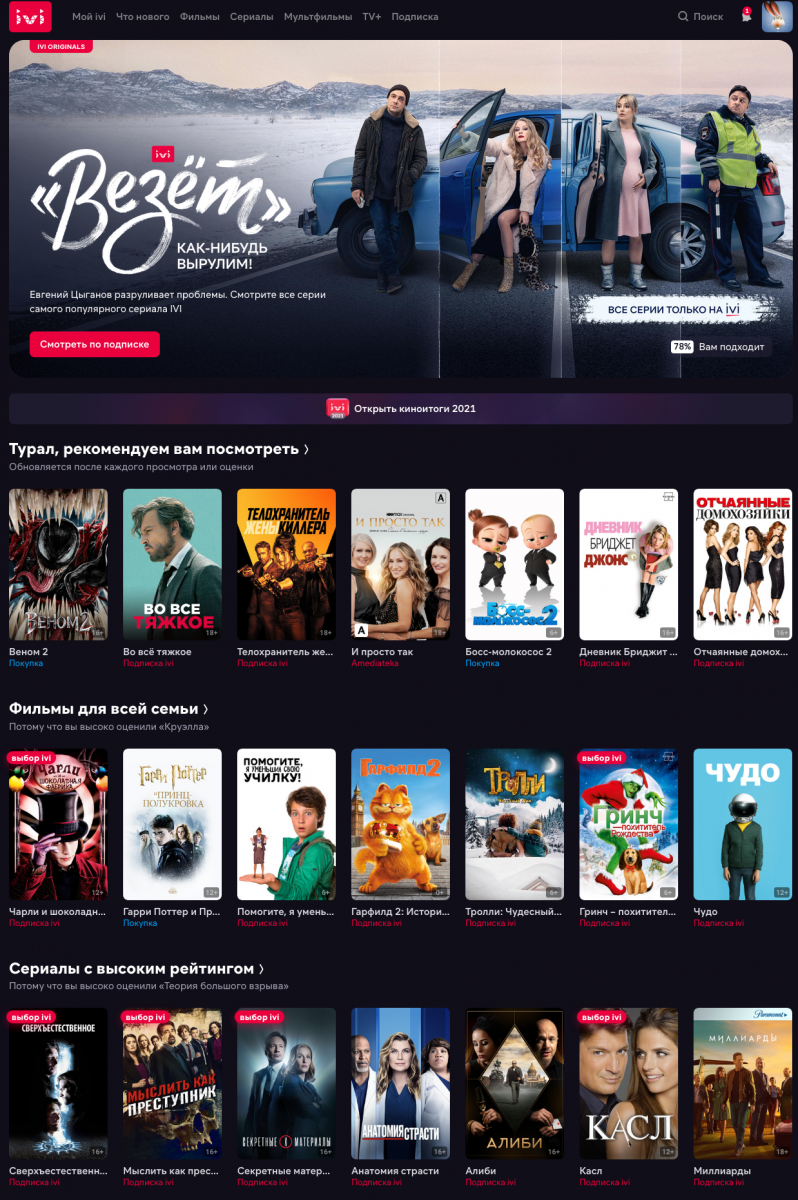
Content, как известно, is the king, вот только количество этих "кингов" сегодня так велико, что особенную ценность приобретают средства, помогающие зрителю из всего многообразия контента выбрать себе что-то по вкусу. Желательно быстро и с некоторой точностью попадания в круг интересов каждого конкретного зрителя. Поэтому рекомендательный сервис сегодня – must have для любого уважающего себя онлайн-кинотеатра. Следующий этап – совершенствование этого сервиса, оттачивание точности рекомендаций, и специалисты в этой области – сегодня буквально на вес золота. Один из таких замечательных людей – Турал Гурбанов, руководитель отдела ML&AI онлайн-кинотеатра ivi подготовил для читателей "Кабельщика" небольшой ликбез о принципах работы рекомендательных сервисов и о тонкостях системы, работающей конкретно в этом онлайн-кинотеатре.

Ориентир на лидеров
Идея создать собственную рекомендательную систему в IVI появилась в конце 2013 года. На тот момент подобные системы не считались чем-то необходимым для успешного медиа сервиса (фокус был скорее на поиске). Тем не менее, уже было достаточно компаний известных в том числе своими рекомендациями контента – movielens, Pandora (музыкальный сервис), last.fm, и конечно же Netflix. Каждая из этих компаний была либо успешным создателем, либо первопроходцем многих подходов, используемых в современных рекомендательных системах, в том числе в рекомендательной системе IVI. Так работы Netflix повлияли на выбор основных алгоритмов рекомендаций, проект Music Genome от Pandora подсказал нам как лучше тегировать фильмы, а movielens рассказал, как лучше объяснять рекомендации конечным пользователям и менеджменту компании.
В 2021 году рекомендательные системы — одна из самых "горячих" областей машинного обучения. Новые подходы и идеи публикуются почти каждую неделю. Мы в IVI стараемся быть в ногу со временем, пробуем применить в нашей области подходы других компаний, а также рассказываем про свои наработки. Так, за последний год мы с переменных успехом пробовали внедрить нейросетевые модели от Netflix, Facebook, Spotify и даже Airbnb. Мы также разработали уникальный способ автоматического формирования главной страницы сервиса, который адаптирует содержимое всей страницы персонально под каждого пользователя.
Какие типы рекомендательных систем существуют в практике видеосервисов? В чем плюсы и минусы каждой из них и почему ivi использует именно гибридную?
Существуют три основных типа рекомендательных систем.
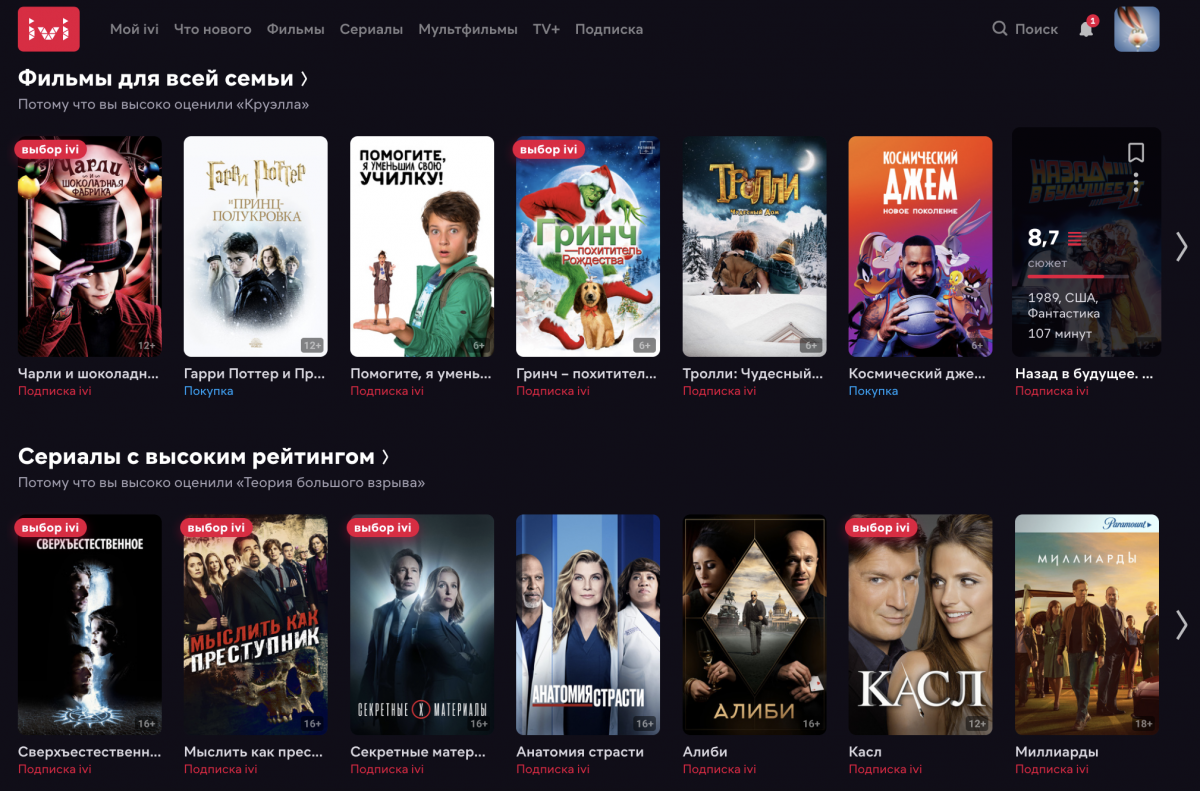
Первый — система, основанная на свойствах контента. Она предлагает пользователям фильмы похожего жанра или с тем же актером в главной роли, что в уже просмотренном фильме. Такая система идеально подходит для поиска контента, похожего на то, что вы смотрели недавно. В то же время подобная система не сильна в поиске "ассоциаций" или "паттернов потребления". Система, основанная на свойствах контента, в своем базовом варианте, не порекомендует шоколад к коньяку или первый эпизод "Звездных Войн" после просмотра шестого.
Второй тип — система коллаборативной фильтрации. В отличие от предыдущего типа, у подобной системы нет проблем с ассоциациями. Коллаборативная фильтрация находит пользователей, чьи вкусы похожи на ваши, и рекомендует вам фильмы, которые понравились этим пользователям и которые вы еще не смотрели. Если вам вместе с некоторым количеством других пользователей IVI понравился сериал "Клиника счастья", а после него эти пользователи начали смотреть сериал "Везёт", то система посоветует его и вам. Эта система, в целом, точнее системы, основанной на контенте, и выдает более разнообразные рекомендации.
Интуитивная прозорливость (от англ. serendipity) коллаборативной фильтрации не всегда работает во благо. Покупая телевизор, вы с большей вероятностью ожидаете увидеть в рекомендациях другие телевизоры, чем батарейки к пульту от телевизора. То есть, в разных ситуациях (контекстах) должны работать разные типы рекомендательных систем.
Рекомендательные системы, объединяющие по определенной логике работу нескольких рекомендательных системы, называются гибридными. Именно такой тип систем используется во многих персонализированных сервисах, в том числе и в ivi. Когда пользователь заходит на главную страницу, он видит рекомендации, построенные несколькими моделями коллаборативной фильтрации, дополняющими работу друг друга. В то же время, на странице фильма, в блоке "смотри также" находятся рекомендации для построения которых используются свойства контента.
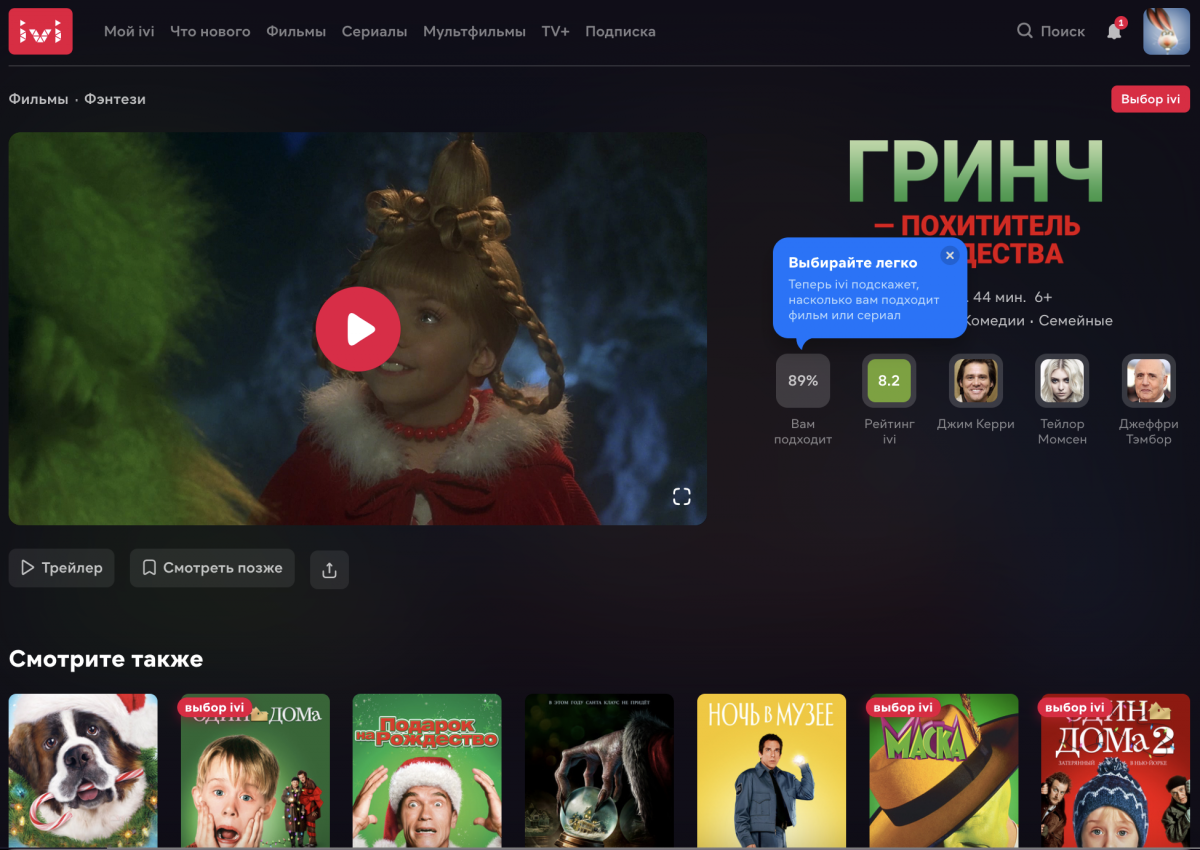
Какие данные нужны для работы рекомендательной системы и как их собирают? Как выстраиваются рекомендации на основе этих данных?
Чтобы построить персональные рекомендации, система должна понимать интересы и предпочтения пользователей. Для этого она анализирует явные и неявные отзывы пользователей о контенте. Используя явные отзывы, такие как оценки или лайки/дизлайки, пользователь явно сообщает системе какой контент ему понравился или не понравился. В случае с неявными отзывами, к которым можно отнести все действия, совершаемые пользователем во время взаимодействия с контентом (клики, просмотры, покупки и т.д.), система делает вывод о пользовательских интересах на основе сравнительного анализа паттернов взаимодействия пользователя с контентом. Например, фильм, который пользователь смотрел несколько раз, скорее всего, нравится пользователю больше, чем тот который он досмотрел лишь до половины.
Хотя на первый взгляд явный отзыв кажется более качественным и достоверным сигналом о предпочтениях пользователя, это не всегда так. Большинство оценок актуальны лишь в моменте и контексте, в которых их поставили – фильм мог понравиться лишь потому, что вы посмотрели его с друзьями. Кроме того, не все пользователи готовы поставить низкую оценку осознанно выбранному фильму, из-за чего количество положительных оценок в среднем больше, чем отрицательных. А еще, многие пользователи предпочитают не оценивать контент, так как это требует дополнительных когнитивных усилий. Подобные факторы отрицательно влияют на качество рекомендаций, поэтому большинство современных рекомендательных систем использует либо комбинацию явных и неявных отзывов, либо только неявные отзывы.
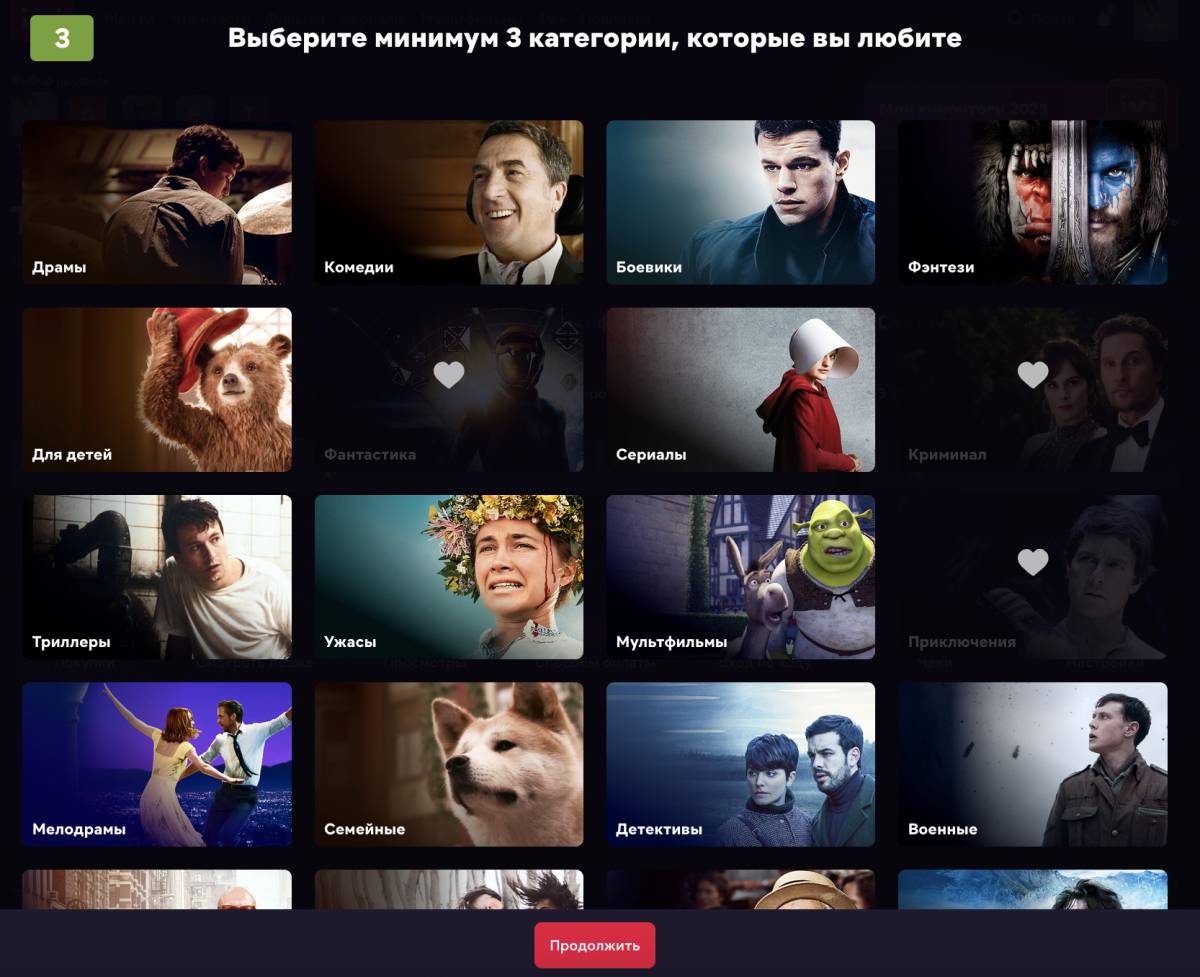
В ivi используется рекомендательная система комбинирующая явные и неявные пользовательские отзывы. Пользователь может явно указать свои предпочтения через оценки, контекстное меню фильма и форму онбординга. В свою очередь система извлекает информацию об интересах пользователя из событий просмотра контента, просмотра постеров фильмов (impression) и покупок.
Чем больше качественных данных о пользователе, контенте и взаимодействие пользователя с контентом доступно рекомендательной системе, тем лучше она понимает интересы пользователя и тем точнее рекомендует ему контент.
Необходимым условием для построения эффективной рекомендательной системы является эффективная система событийной аналитики. В ivi своя собственная система событийной аналитики, за работу которой отвечает команда программистов, дата- и DevOps-инженеров. Команда обеспечивает своевременную и бесперебойную доставку событий до хранилищ данных, а также оперативный доступ к огромным массивам собранной информации. Помимо нужд рекомендательной системы, данные используются для анализа поведения пользователей, повышения качества продукта, а также принятия стратегических бизнес-решений.
Путь от рекомендаций до рекомендаций
Действия, которые пользователь совершает в приложениях, собираются и сохраняются в хранилища данных. Из этих хранилищ мы можем узнать какие постеры пользователь видел в приложении, на что кликал, по каким страницам переходил, какой фильм и на каком устройстве смотрел и многое другое. Обогащаясь знаниями из различных справочников, например информацией о дате производства фильма или актеров, которые там снимались, эти данные используется для обучения рекомендательных моделей. Анализируя данные, модели учатся идентифицировать паттерны интересов пользователя и затем строят рекомендации на их основе.
В нашем случае рекомендации строятся "на лету", то есть, в момент, когда пользователь открывает соответствующую страницу в приложении. Если упростить все до нескольких шагов, то построение рекомендаций выглядит следующим образом. В момент открытия страницы клиентское приложение запрашивает рекомендации у рекомендательной системы. Система ходит в хранилище за данными, которые нужны для ее работы. Полученные данные прогоняются через обученные рекомендательные модели, которые и строят рекомендации фильмов. Полученные фильмы могут подвергаться дополнительной фильтрации, которая учитывает различные бизнес-правила (учет возраста пользователя) или особенности устройства (ширину экрана, доступность контента на устройстве). Отфильтрованный список фильмов передается в клиентское приложение, которое красиво отображает их пользователю.
Зависят ли рекомендации от того, с какого устройства пользователь смотрит контент?
Рекомендации адаптируются под устройства как с точки зрения содержимого, так и с точки зрения отображения. Для построения рекомендаций учитывается популярность фильмов на каждом устройстве, а также ширина экрана устройства и возможности по воспроизведению определенных типов видео. Например, нет смысла рекомендовать 4К контент на устройстве, которое не может его показать.
Какие специалисты отвечают за работу системы рекомендаций?
За создание, развитие и поддержку рекомендательной системы в ivi отвечает отдельная кросс-функциональная команда, состоящая из 13 человек, среди которых три разработчика, по два дата-аналитика, ML- и QA-инженера, DevOps-инженер, тимлид, технический менеджер и продукт оунер. Дата-аналитики анализируют работу рекомендательной системы как продукта, а также занимаются поиском инсайтов в данных, способных улучшить качество моделирования предпочтений пользователей. ML-инженеры используют вводные от дата-аналитиков для создания новых рекомендательных моделей и их внедрение в рекомендательную систему. Разработчики и DevOps-инженер отвечают за оптимальную, с точки зрения потребляемых ресурсов и времени ответа, работу системы и за инфраструктурные задачи. QA-инженеры делают все, чтобы минимизировать количество потенциальных багов в продакшне.
Как проверяют эффективность рекомендаций?
Все рекомендательные модели обучаются и валидируются на исторических данных. Изначально, качество моделей оценивается на "офлайн" метриках. Пример такой метрики, hit ratio – процент раз, когда модель угадала фильм, который был интересен пользователю. Оценка моделей на офлайн метриках является популярной практикой, однако значения этих метрик не всегда коррелируют с реальным качеством рекомендаций. Причина кроется в том, что исторические данные – это продукт взаимодействия пользователя с существующей рекомендательной системой. Как следствие, в большинстве случаев, самой оптимальной моделью на офлайн метриках является модель, работавшая в момент сбора исторических данных (feedback loop). Хотя на практике существует множество способов смягчения данной проблемы, офлайн метрики чаще используют для проверки работоспособности модели. Тестирование качества рекомендаций происходит на реальных пользователях в "онлайн" части при помощи АБ-тестов.
Бывали ли когда-нибудь сбои, ошибки в работе рекомендательной системы? Как их исправили?
Активно развивающиеся системы склонны к ошибкам. Ошибки могут быть двух типов – технические и логические. Технические ошибки обычно приводят к частичному или полному отказу системы и как следствие пользователь не получает рекомендации. Логические ошибки не отражаются на работоспобности самой системы, но могут сделать рекомендации некорректными и неэффективными. Например, из-за логической ошибки мы можем начать рекомендовать детский контент взрослому пользователю.
Разработчики и QA-инженеры делают все, чтобы не допустить появление технических или логических ошибок в продакшн рекомендациях. Но иногда ошибки все же просачиваются. В основном это происходит во время запуска нового функционала. Например, из-за логической ошибки мы некоторое время показывали подписчикам не самый интересный бесплатный контент. Из-за того, что весь новый функционал мы запускаем через АБ-тестирование, подобные ошибки не сложно локализировать – мы видим изменения, которые не ожидаем увидеть. В таком случае тест останавливается, а функционал отправляется на доработку.
Сценарии рекомендаций
От редакции пришел еще такой комментарий: "Очень интересны скрипты, условно говоря, какие зависимости и взаимосвязи между различными типами контента можно назвать. Потому что в ivi я вижу несколько иную систему рекомендаций, нежели в том же Netflix: там я могу запросить какой-то фильм, и он предложит другие фильмы, возможно не этой же категории, но подходящие мне. А в ivi я вижу более линейные рекомендации (зомби = зомби, по ключевым словам названий), но могу ошибаться".
Видимо, редакции интересны те самые рекомендательные модели, сценарии. Давайте вставим здесь несколько примеров, какие рекомендательные сценарии используются в ivi. И объясним, есть ли в плане этих моделей отличие от Netflix и в чем оно.
Если говорить про сценарии, то их несколько.
- Персональные рекомендации контента – используются для сортировки контента по релевантности. Их можно встретить в подборках на главной странице IVI. Порядок контента в каждой подборке определен релевантностью контента пользователю. Эти рекомендации строятся на основе моделей коллаборативной фильтрации и популярности контента.
- Персональные рекомендации подборок – используются для сортировки подборок на главной странице. Порядок подборок на главной странице определяется по суммарной релевантности контента, входящего в эту подборку. Эти рекомендации также строятся на основе моделей коллаборативной фильтрации и популярности контента.
- Сегментированная сортировка блоков на главной – используется для оптимизации главной страницы под паттерны использования сервиса пользователем. Порядок блоков определяет востребованность блока сегментом пользователей, смотрящих IVI с определенного типа устройства в определенной стране. Для построения этих рекомендаций используется технология многоруких бандитов.
- Рекомендации похожего контента – используются для поиска похожего контента. Данные рекомендации строятся на основе данных о схожести контента друг с другом с точки зрения пользователей, которые смотрят этот контент и свойств этого контента.
P.S. от редакции: если у вас остались еще вопросы к Туралу относительно тонкостей работы рекомендательной системы ivi, их можно оставить под публикацией или направить в редакцию "Кабельщика".
- Войдите или зарегистрируйтесь, чтобы оставлять комментарии
Об авторе










